Benchmarks
If you wish to decide what model/backend to use, give the benchmark utility a try. It will return you various indicators to help you decide, all in the shape of a comprehensive report.
To run the benchmark:
knwler benchmark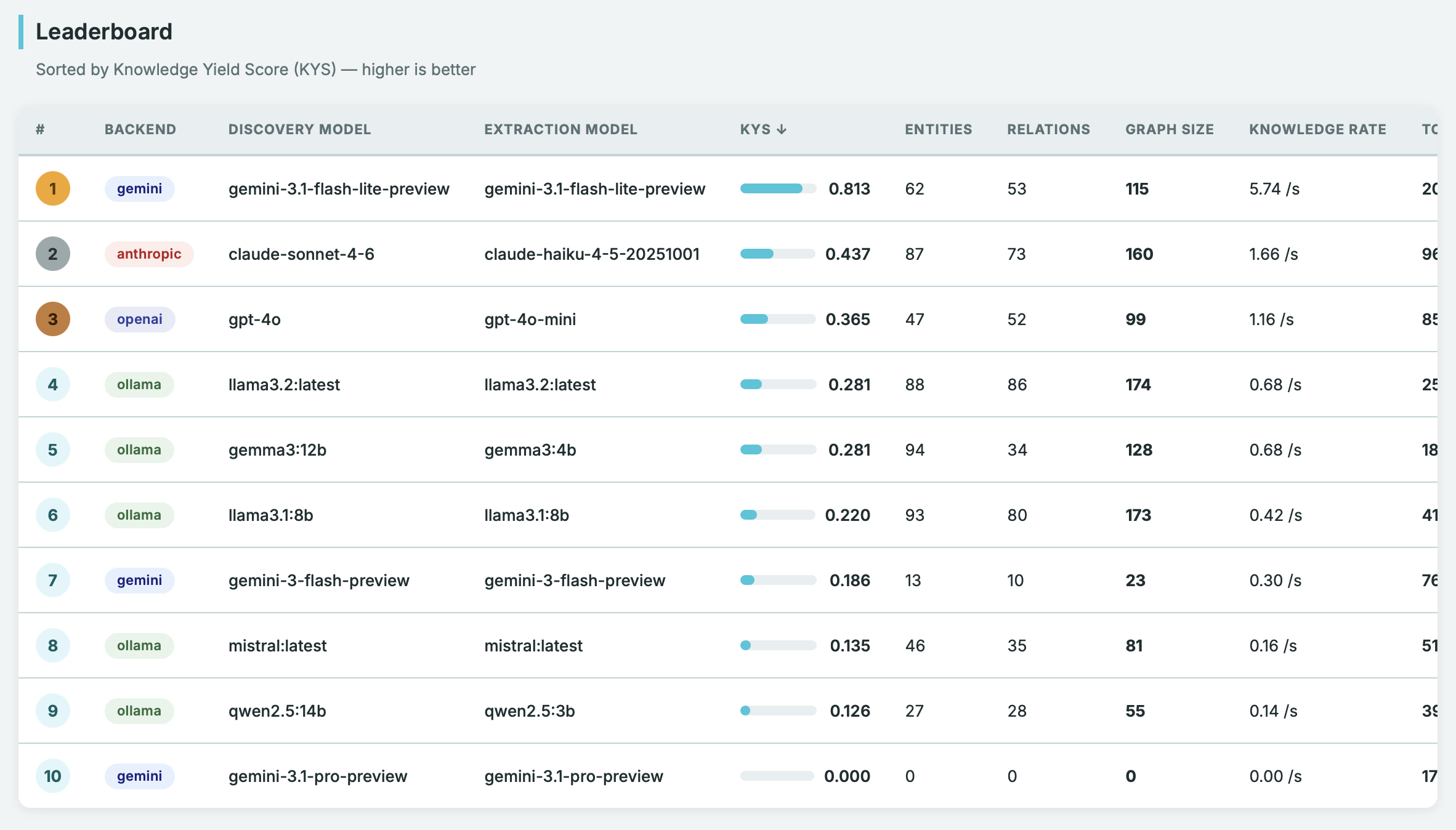
You can define the grid of configuration inside the file:
grid = {
"ollama": [
{
"discovery_model": "qwen2.5:14b",
"extraction_model": "qwen2.5:3b",
},
{
"discovery_model": "gemma3:12b",
"extraction_model": "gemma3:4b",
},
{
"discovery_model": "llama3.1:8b",
"extraction_model": "llama3.1:8b",
},
],
"openai": [
{
"discovery_model": "gpt-4o",
"extraction_model": "gpt-4o-mini",
},
],
"anthropic": [
{
"discovery_model": "claude-sonnet-4-6",
"extraction_model": "claude-haiku-4-5-20251001",
},
],
}The metric is defined as follows:
\[ \text{KYS} = \sqrt{ \left( \frac{\text{graph\_size}}{\max(\text{graph\_size})} \right) \cdot \left( \frac{\min(\text{total\_time})}{\text{total\_time}} \right) } \]
This Knowledge Yield Score is a geometric mean of normalized quality and speed - like an F-score, it can’t be gamed by being great at only one dimension.
The report is generated via a Jinja template and you can customize it as needed.